Title here
Summary here
INSERT INTO is used to insert a row of data into a given table.
INSERT INTO table (column0, ...)
VALUES
(value0, ...);INSERT INTO "collections" ("id", "title", "accession_number", "acquired")
VALUES (1, 'Profusion', '56.257', '1996-04-12');This command requires the list of columns in the table that will receive the values to be added to each column in the same order.
We can insert more rows by running the inserting multiple times, but typing out the primary key might result in error.
SQLite fills out the primary key automatically by checking for the highest value in id and incrementing it by one.
This can be done by leaving out the id column altogether while inserting the row.
Other constraints
Cannot insert a similar id which is given UNIQUE constraint.
When there is NOT NULL, then NULL values cannot be added.
INSERT INTO can be comma separated to insert multiple rows.
INSERT INTO table (column0, ...)
VALUES
(value0, ...),
(value1, ...),
...;INSERT INTO "collections" ("title", "accession_number", "acquired")
VALUES
('Imaginative landscape', '56.496', NULL),
('Peonies and butterfly', '06.1899', '1906-01-01');The id is auto incremented so left out, the date is unknown so given as NULL.
Data can be stored in a comma-separated-values format where values in each row are separated by a comma and rows are in in separate rows.

This file can be imported into SQLite database.
mfa.csv is the file containing the data needed.
If the names of the column matches the names according to our schema in database.
We can import the CSV by running a SQLite command.
(A SQLite commands do not need " " )
.import --csv --skip 1 mfa.csv collections--csv indicates we are importing CSV file (to specify they are comma separated)
--skip 1 indicated that the first row needs to be skipped or not inserted into the table (as they are column headings which are already present in the table)
mfa.csv colections the data from CSV file is copied into the table.
Most of the CSV files will not contain any primary key values like they were present here.
title,accession_number,acquired
Profusion of flowers,56.257,1956-04-12
Farmers working at dawn,11.6152,1911-08-03
Spring outing,14.76,1914-01-08
Imaginative landscape,56.496,
Peonies and butterfly,06.1899,1906-01-01First we will delete the data in the collections table
DELETE FROM "collections";
By leaving out the row data in the end, it deletes all the rows in the table.
The schema has 4 rows and the CSV has 3 rows so we will have to use a temporary table first:
.import --csv mfa.csv tempHere skip is not used and SQLite will take the first row and convert those to column names of the new temp table.
Next we can select the data from temp without the primary key by a query and move it into collections. The id will be added automatically.
INSERT INTO "collections" ("title", "accession_number", "acquired")
SELECT "title", "accession_number", "acquired" FROM "temp";To clean up the data base we can drop the temp table
DROP TABLE "temp";
INSERT INTO table0 (column0, ...)
SELECT column0, ... FROM table1;Insert into the table 0 columns the result of the query of table 1. The Columns have to allign.
DELETE FROM table WHERE condition;Without the condition all rows will be deleted from the table.
DELETE FROM table;
DELETE FROM "collections"
WHERE "title" = 'Spring outing';
DELETE FROM "collections"
WHERE "acquired" IS NULL;So sprint outing and the other one with acquired date NULL both will be deleted.
To delete the ones which are older than 1909
DELETE FROM "collections"
WHERE "acquired" < '1909-01-01';Complications in deleting can impact the integrity of a database. Foreign key constraints are a good example. A foreign key column references the primary key of a different table. If we were to delete the primary key, the foreign key column would have nothing to reference!

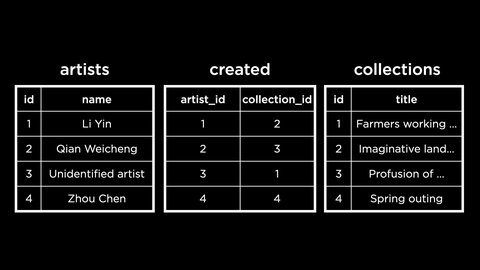
Here if we choose to delete the Undefined artist from the artists table, it will cause an error as the id of that is being refereed in the created table under artist_id.
One possibility is delete the corresponding row in created beforehand and then delete the one in the artists table.
DELETE FROM "created"
WHERE "artist_id" = (
SELECT "id" FROM "artists" WHERE "name" = 'Undefined artist'
);Once the affiliation is deleted, the artist data can be deleted
DELETE FROM "artists"
WHERE "name" = 'Undefined artist';Another possibility of deleting an ID referred by a foreign key is deleted by using ON DELETE followed by action to be taken.
FOREIGN KEY("artist_id") REFERENCES "artists"("id")
ON DELETE ...ON DELETE RESTRICT:
Restricts us from deleting IDs when the foreign key constraint is violated.
ON DELETE NO ACTION:
Deletion of IDs that are referenced by a foreign key and nothing happens.
ON DELETE SET NULL:
Deletion of IDs that are referenced by a foreign key and sets the foreign key reference to NULL
ON DELETE SET DEFAULT:
does the same as the previous, but allows us to set a default value instead of NULL.
ON DELETE CASCADE:
allows the deletion of IDs that are referenced by a foreign key and also proceeds to cascadingly delete the referencing foreign key rows.
For example, if we used this to delete an artist ID, all the artist’s affiliations with the artwork would also be deleted from the created table. (similar to previous two step approach)
Using these in the schema shows
FOREIGN KEY("artist_id") REFERENCES "artists"("id") ON DELETE CASCADE
FOREIGN KEY("collection_id") REFERENCES "collections"("id") ON DELETE CASCADEThe ON DELETE CASCADE will delete the rows it was referenced also when we run
DELETE FROM "artists"
WHERE "name" = 'Undefined artist';A deleted ID can be made to be repurposed for a new row, this can be done by using AUTOINCREMENT keyword while creating a column.
To change the data already in the table,
UPDATE table
SET column0 = value0, ...
WHERE condition;UPDATE "created"
SET "artist_id" = (
SELECT "id" FROM "artists" WHERE "name" = 'Li Yin'
)
WHERE "collectio_id" = (
SELECT "id" FROM "collections" WHERE "title" = 'Farmers working at dawn'
);The value of artist_id is changed where the collection_id was of the given painting.
SELECT "title", COUNT("title") FROM "votes" GROUP BY "title";To show the unique titles with their counts. (if the names match)
(SQLite Scalar functions to modify the data)
TRIM to remove leading and trailing white space.
UPDATE "votes" SET "title" = trim("title");UPPER LOWER to change cases
UPDATE "votes" SET "title" = upper("title");Manually changing using conditions
UPDATE "votes" SET "title" = 'FARMERS'
WHERE "title" = 'FAMER';Using the LIKE to update things that looks like a condition, not exactly = to.
UPDATE "votes" SET "title" = 'FARMERS'
WHERE "title" LIKE 'FA%';Like is case insensitive.
A SQL statement that runs when other statement is run like an Insert, Update, Delete.
Having a collections table and a transactions table.
Anything removed from collections appears as a sold item in transactions. Anything added will show up as purchases.
CREATE TRIGGER name
BEFORE INSERT ON table
FOR EACH ROW
BEGIN
...:
END;name is used to identify them, similar to a table name.
AFTER or BEFORE decides when should the statement run.
BEFORE INSERT ON table
BEFORE DELETE ON table
BEFORE UPDATE OF column ON tableFOR EACH ROW specifies how many times a statement should be run, if two rows are deleted then it should run two times.
The statement or multiple statements that have to be run on a trigger will go between BEGIN and END;
The current schema .schema
CREATE TABLE "collections" (
"id" INTEGER,
"title" TEXT NOT NULL,
"accession_number" TEXT NOT NULL UNIQUE;
"acquired" NUMERIC,
PRIMARY KEY("id")
);
CREATE TABLE "artists" (
"id" INTEGER,
"name" TEXT NOT NULL,
PRIMARY KEY("id")
);
CREATE TABLE "created" (
"artist_id" INTEGER,
"collection_id" INTEGER,
PRIMARY KEY("artist_id", "collection_id"),
FOREIGN KEY("artist_id") REFERENCES "artists"("id")
ON DELETE CASCADE,
FOREIGN KEY("collection_id") REFERENCES "collections"("id") ON DELETE CASCADE
);Making the transactions table
CREATE TABLE "transactions" (
"id" INTEGER,
"title" TEXT,
"actions" TEXT,
PRIMARY KEY("id")
);Making a trigger, to run before deletion happens in collections table, to insert that data into transactions table.
CREATE TRIGGER "sell"
BEFORE DELETE ON "collections"
FOR EACH ROW
BEGIN
INSERT INTO "transactions"("title", "action")
VALUES (OLD."title", 'sold');
END;(This will become part of the schema.)
In Triggers there is access to the key words OLD and NEW.
OLD is the row we just deleted from. OLD."title" gives access to the title of the row that was deleted.
NEW is the recently added row.
CREATE TRIGGER "buy"
BEFORE INSERT ON "collections"
FOR EACH ROW
BEGIN
INSERT INTO "transactions"("title", "action")
VALUES (NEW."title", 'bought');
END;Not completely dropping the row but having it in some other place,
Or another way is to just have a column which monitors if the row is deleted or not by using 0 1
The filter can be done to show only those which are not having 1 at deleted.
Adding a new column, with default value 0
ALTER TABLE "collections" ADD COLUMN "deleted" INTEGER DEFAULT 0;Now the value of deleted can be updated from 0 to 1.
UPDATE "collections" SET "deleted" = 1 WHERE "title" = 'Farmers';To filter according to deleted
SELECT * FROM "collections" WHERE "deleted" != 1;
SELECT * FROM "collections" WHERE "deleted" = 1;The advantage is data is not deleted, it can still be accessed but that has other issues when handling user data.