Processes executing concurrently in an operating system can be either independent or cooperating.
Independent Process: A process that cannot affect or be affected by other processes. These processes do not share data with others.
Cooperating Process: A process that can be affected by or affect other processes. These processes share data and require communication to synchronize and exchange information.
Reasons for Process Cooperation:
Information Sharing: Multiple processes may need access to the same data (e.g., a shared file).
Computation Speedup: Large tasks can be broken into smaller sub-tasks to run in parallel, speeding up execution.
Modularity: A system can be constructed modularly by dividing functionality into separate processes or threads.
Convenience: Allows multiple tasks to run concurrently, improving system efficiency.
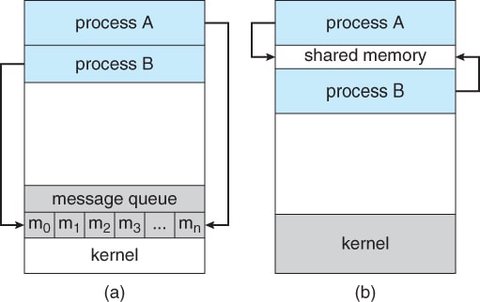
Cooperating processes require an Inter-Process Communication (IPC) mechanism to exchange data and synchronize their operations. The two primary IPC models are Shared Memory and Message Passing.
3.12 Communication Models
3.4.1 Shared-Memory Systems
In shared-memory systems, cooperating processes communicate by sharing a region of memory. This allows processes to exchange information by reading and writing data to the shared memory region.
How Shared Memory Works:
A process creates a shared memory segment in its address space.
Other processes that wish to communicate using this memory must attach the shared memory to their address space.
These processes can then exchange data by reading and writing in the shared region.
The OS does not control the data format or the memory location; this responsibility lies with the processes.
Synchronization:
Processes must ensure that they do not write to the same memory location simultaneously. One common problem in cooperative processes is the Producer-Consumer problem.
Producer Process: Produces data.
Consumer Process: Consumes data produced by the producer.
To allow both processes to run concurrently, they need a shared buffer a region of memory where the producer can place data, and the consumer can retrieve it.
There are two types of buffers used:
Unbounded Buffer: No limit on the buffer size. The producer can continue producing items even if the consumer is slower in consuming. The consumer may need to wait for new items, but the producer is not blocked.
Bounded Buffer: The buffer has a fixed size. The producer must wait if the buffer is full, and the consumer must wait if the buffer is empty.
The shared buffer is often implemented as a circular array with two logical pointers:
In Pointer: Points to the next available position in the buffer.
Out Pointer: Points to the next item to be consumed.
Synchronization Mechanism:
To ensure the producer and consumer operate efficiently, synchronization mechanisms such as mutexes or semaphores are often used to avoid race conditions and ensure mutual exclusion.
3.4.2 Message Passing Systems
Message passing allows processes to communicate and synchronize without sharing the same address space, making it especially useful in distributed systems where processes may reside on different computers connected by a network.
Message Passing Operations
Message passing typically provides at least two operations:
send(message): Send a message to another process.
receive(message): Receive a message from another process.
Messages can be fixed or variable in size:
Fixed-sized messages: Easier system implementation, but harder to program.
Variable-sized messages: More complex system-level implementation, but simpler for the programmer.
Message Passing Implementation Models
Message passing systems can be implemented using different methods, including:
Direct or Indirect Communication
Synchronous or Asynchronous Communication
Automatic or Explicit Buffering
3.4.2.1 Naming
Processes communicating via message passing must refer to each other. This can be done via direct or indirect communication.
Direct Communication
Each process explicitly names the sender or receiver.
send(P, message): Send a message to process P.
receive(Q, message): Receive a message from process Q.
Properties of direct communication:
A communication link is automatically established between every pair of processes that wish to communicate.
Each pair of processes has exactly one link.
Symmetric addressing: Both processes must name each other.
A variant is asymmetric addressing, where only the sender names the recipient; the recipient is not required to name the sender. :
send(P, message): Send a message to process P.
receive(id, message): Receive a message from any process, with id set to the name of the sender.
The disadvantage of both symmetric and asymmetric communication schemes is the limited modularity of the resulting process definitions. These schemes rely on hard-coding techniques, where identifiers must be explicitly stated, which reduces flexibility and makes the system less modular. Such hard-coding is generally less desirable than using techniques that involve indirection, where the identities of communicating processes are more dynamically determined.
Indirect Communication
With indirect communication, processes communicate via mailboxes (or ports), which are abstract objects where messages are placed and retrieved.
send(A, message): Send a message to mailbox A.
receive(A, message): Receive a message from mailbox A.
Properties of indirect communication:
Communication only happens between processes with a shared mailbox.
A link can involve more than two processes, as multiple processes can communicate through a single mailbox.
There are two types of mailbox ownership:
Process-owned mailbox: A process can only receive messages through its mailbox, and it disappears when the process terminates.
OS-owned mailbox: A mailbox exists independently of any process, and the OS manages its creation, deletion, and message passing.
3.4.2.2 Synchronization
Synchronization determines how send and receive operations block or proceed.
Blocking Send: The sender is blocked until the message is received or placed in the mailbox.
Non-blocking Send: The sender sends the message and continues execution without waiting.
Blocking Receive: The receiver is blocked until a message is available.
Non-blocking Receive: The receiver retrieves either a valid message or a null.
For example, in a Producer-Consumer problem:
The producer sends a message using a blocking send and waits until the message is received.
The consumer receives a message via a blocking receive, waiting until a message is available.
3.4.2.3 Buffering
Messages exchanged between processes are held in temporary queues. These queues can be implemented in three ways:
Zero-capacity Queue: No messages can be stored. The sender is blocked until the receiver retrieves the message. This type of queue is sometimes referred to as a message system with no buffering.
Bounded-capacity Queue: The queue has a finite size. The sender is blocked if the queue is full.
The queue has a finite size (e.g., at most n messages can reside in it). If the queue is not full when a new message is sent, the message is placed in the queue (either the message is copied or a pointer to the message is kept), and the sender can continue execution without waiting. If the queue is full, the sender is blocked until space becomes available.
Unbounded-capacity Queue: The queue can hold an unlimited number of messages. The sender never blocks, regardless of the queue’s size.
Systems with bounded or unbounded queues are referred to as automatic buffering systems, while a zero-capacity queue system is referred to as having no buffering.
Summary for IPC
Direct vs Indirect Communication: Direct communication requires processes to explicitly name each other, whereas indirect communication uses mailboxes that can hold messages from multiple processes.
Synchronous vs Asynchronous: Synchronous (blocking) communication blocks the sender or receiver until the operation completes, while asynchronous (non-blocking) communication allows the sender or receiver to continue without waiting.
Buffering Types: Message queues can be zero-capacity (no buffering), bounded-capacity (limited storage), or unbounded-capacity (unlimited storage), each with different performance trade-offs.
Message passing is particularly advantageous in distributed systems and when small data exchanges between processes are needed. It is generally slower than shared memory communication because it requires kernel intervention, but it provides easier implementation and avoids synchronization issues.
Summary of Process Chapter
*Process Concept:
A process is a program in execution and changes state during its lifetime. The states include:
New: The process is being created.
Ready: The process is ready to execute, waiting for the CPU.
Running: The process is currently executing.
Waiting: The process is waiting for an event (like I/O completion).
Terminated: The process has finished execution.
Process Control Block (PCB):
Each process is represented by its own Process Control Block (PCB) in the OS.
A process that is not executing is placed in a waiting queue, which can be either an I/O request queue or a ready queue.
The ready queue holds processes that are ready to execute and waiting for the CPU.
Scheduling:
Long-term (Job) Scheduling: Selects processes to contend for the CPU, influenced by resource allocation, especially memory management.
Short-term (CPU) Scheduling: Selects one process from the ready queue to execute.
Parent-Child Process Relationships:
Parent processes can create child processes.
The parent can either wait for the child to terminate before proceeding or allow them to execute concurrently.
Reasons for concurrent execution include:
Information sharing
Computation speedup
Modularity
Convenience
Types of Processes:
Independent Processes: These processes do not affect or share data with other processes.
Cooperating Processes: These processes interact with each other and require an Interprocess Communication (IPC) mechanism.
Interprocess Communication (IPC):
Shared Memory: Processes communicate by reading/writing to shared memory regions. The OS provides the memory, but application programmers manage the communication.
Message Passing: Processes exchange messages. The OS typically provides the communication mechanism.
Both schemes (shared memory and message passing) can be used simultaneously in an OS.
Communication Methods in Client-Server Systems:
Sockets: An endpoint for communication, forming a connection between applications.
Remote Procedure Calls (RPCs): A process calls a procedure on a remote application.
Pipes: Provide simple communication between processes.
Ordinary pipes: Used between parent and child processes.
Named pipes: Allow communication between unrelated processes.
Summary for Threads
Definition:
A thread is a single sequence of instructions within a process. Each thread within a process shares the same memory space, but they can execute independently. A multithreaded process contains multiple threads running concurrently within the same process. This allows for parallelism, enabling efficient use of CPU resources.
Benefits of Multithreading:
Increased Responsiveness: When an application uses multiple threads, one thread can handle user inputs (such as clicking or typing) while other threads perform background tasks. This results in a smoother user experience, as the program does not freeze while executing other tasks.
Resource Sharing: Threads within the same process share the same memory space, which means they can directly access shared data (variables, structures) without the need for complex inter-process communication (IPC). This resource sharing simplifies data management and improves efficiency.
Economy: Threads are lighter-weight compared to processes. Creating and managing threads generally involves less overhead than managing processes because threads share the same address space and resources within a process. This makes context switching faster compared to processes.
Scalability: Multithreaded programs can be optimized to use multiple CPU cores. On multi-core systems, threads can run concurrently on different cores, significantly improving performance for CPU-bound tasks and enabling the application to scale effectively.
Types of Threads:
User-Level Threads: These threads are created and managed by the user-level thread library (e.g., POSIX Pthreads), not by the operating system. The kernel is unaware of their existence, meaning it cannot schedule or manage them directly. Since no kernel intervention is needed, user-level threads are faster to create, destroy, and manage. However, if a user-level thread is blocked (for example, waiting for I/O), the entire process can be blocked because the kernel doesn’t recognize the other threads in the process.
Kernel-Level Threads: These threads are created and managed by the operating system kernel. The kernel schedules these threads and is aware of their existence. If one kernel thread is blocked, the operating system can schedule another thread from the same process. Kernel-level threads are slower to create and manage compared to user-level threads due to kernel intervention, but they provide better concurrency and responsiveness because the kernel manages the threads.
Thread Models:
Many-to-One Model: In this model, multiple user-level threads are mapped to a single kernel thread. This model allows multiple threads within a process to run concurrently from the user’s perspective, but the operating system can only schedule one kernel thread at a time. If one user thread blocks, the entire process may be blocked. This model is less efficient for multitasking because it does not utilize multiple CPUs effectively.
One-to-One Model: In this model, each user-level thread corresponds to a kernel thread. This allows each thread to be scheduled independently by the operating system. If a thread is blocked, others in the same process can still run. The one-to-one model can take full advantage of multi-core systems, making it more scalable, but it requires more resources because each thread needs its own kernel thread.
Many-to-Many Model: This model multiplexes many user threads onto a smaller or equal number of kernel threads. This allows a process to use multiple kernel threads while still managing many user threads. This model provides a good balance between user-level and kernel-level management, allowing efficient use of resources while preventing some of the limitations of the many-to-one model.
Operating System Support for Threads:
Modern operating systems, such as Windows, Mac OS X, Linux, and Solaris, provide support for kernel-level threading. They provide mechanisms to create, manage, and schedule threads. In these systems, the kernel is responsible for managing thread execution, synchronization, and scheduling, which allows for efficient multitasking and resource management.
Thread Libraries:
Thread libraries offer an Application Programming Interface (API) that helps developers create and manage threads. Three primary thread libraries include:
POSIX Pthreads: A popular threading library for Unix-like operating systems. It provides a set of functions for creating and managing threads.
Windows threads: The threading API provided by Microsoft Windows. It allows developers to create, manage, and synchronize threads on Windows-based systems.
Java threads: The Java programming language has built-in support for multithreading. It provides the Thread class and Runnable interface to create and manage threads in Java applications.
Implicit Threading:
In implicit threading, the creation and management of threads are handled by compilers and runtime libraries, rather than the application programmer. This allows developers to focus on writing code without worrying about the details of thread management.
Thread Pools: A collection of pre-created threads that can be reused to execute tasks. Thread pools manage the lifecycle of threads automatically, reducing the overhead of creating and destroying threads.
OpenMP: A set of compiler directives that allow developers to parallelize their code using threads without explicitly creating them. OpenMP is widely used in scientific computing.
Grand Central Dispatch (GCD): A threading API used by Apple in Mac OS X and iOS to manage concurrency. GCD handles the creation, scheduling, and execution of threads automatically, allowing developers to write parallel programs with ease.
Challenges in Multithreading:
Multithreaded programs introduce several challenges for developers, including:
Semantics of fork() and exec() system calls: The behavior of these system calls can change in a multithreaded environment. For example, fork() creates a new process, but it only copies the calling thread in some systems, not all threads, which can lead to unexpected behavior.
Signal Handling: In a multithreaded program, signals can be delivered to any thread, making signal handling more complex. This can cause issues in terms of which thread should handle specific signals (e.g., termination signals).
Thread Cancellation: Threads may need to be canceled in response to certain conditions. Proper cancellation handling is required to prevent resource leaks or inconsistent states.
Thread-local Storage (TLS): TLS allows each thread to have its own private data. Managing TLS can be tricky when using multiple threads that need access to specific data.
Scheduler Activations: In some systems, threads are scheduled by the kernel, but the user-level thread library must also be activated to schedule threads. This complex interaction between kernel scheduling and user-level management requires careful design.